سوالات متداول
تستهای من بسیار کند هستند
وقتی از @wdio/ocr-service استفاده میکنید، شما از آن برای سرعت بخشیدن به تستهای خود استفاده نمیکنید، بلکه از آن استفاده میکنید چون پیدا کردن عناصر در برنامه وب/موبایل خود را سخت میبینید و میخواهید راه سادهتری برای پیدا کردن آنها داشته باشید. و همه ما امیدواریم بدانیم که وقتی چیزی میخواهید، چیزی دیگر را از دست میدهید. اما.... راهی وجود دارد که @wdio/ocr-service را سریعتر از حالت عادی اجرا کنید. اطلاعات بیشتر در این مورد را میتوانید اینجا بیابید.
آیا میتوانم دستورات این سرویس را با دستورات/سلکتورهای پیشفرض WebdriverIO ترکیب کنم؟
بله، میتوانید این دستورات را ترکیب کنید تا اسکریپت خود را حتی قدرتمندتر کنید! توصیه این است که تا حد امکان از دستورات/سلکتورهای پیشفرض WebdriverIO استفاده کنید و فقط زمانی از این سرویس استفاده کنید که نمیتوانید یک سلکتور منحصر به فرد پیدا کنید یا سلکتور شما بسیار شکننده خواهد شد.
متن من پیدا نمیشود، چطور ممکن است؟
ابتدا، درک فرآیند OCR در این ماژول مهم است، پس لطفاً این صفحه را بخوانید. اگر هنوز نمیتوانید متن خود را پیدا کنید، ممکن است موارد زیر را امتحان کنید.
ناحیه تصویر خیلی بزرگ است
وقتی ماژول نیاز به پردازش منطقه بزرگی از اسکرینشات دارد، ممکن است متن را پیدا نکند. میتوانید با ارائه یک haystack هنگام استفاده از دستور، ناحیه کوچکتری ارائه دهید. لطفاً دستورات را بررسی کنید که کدام دستورات از ارائه haystack پشتیبانی میکنند.
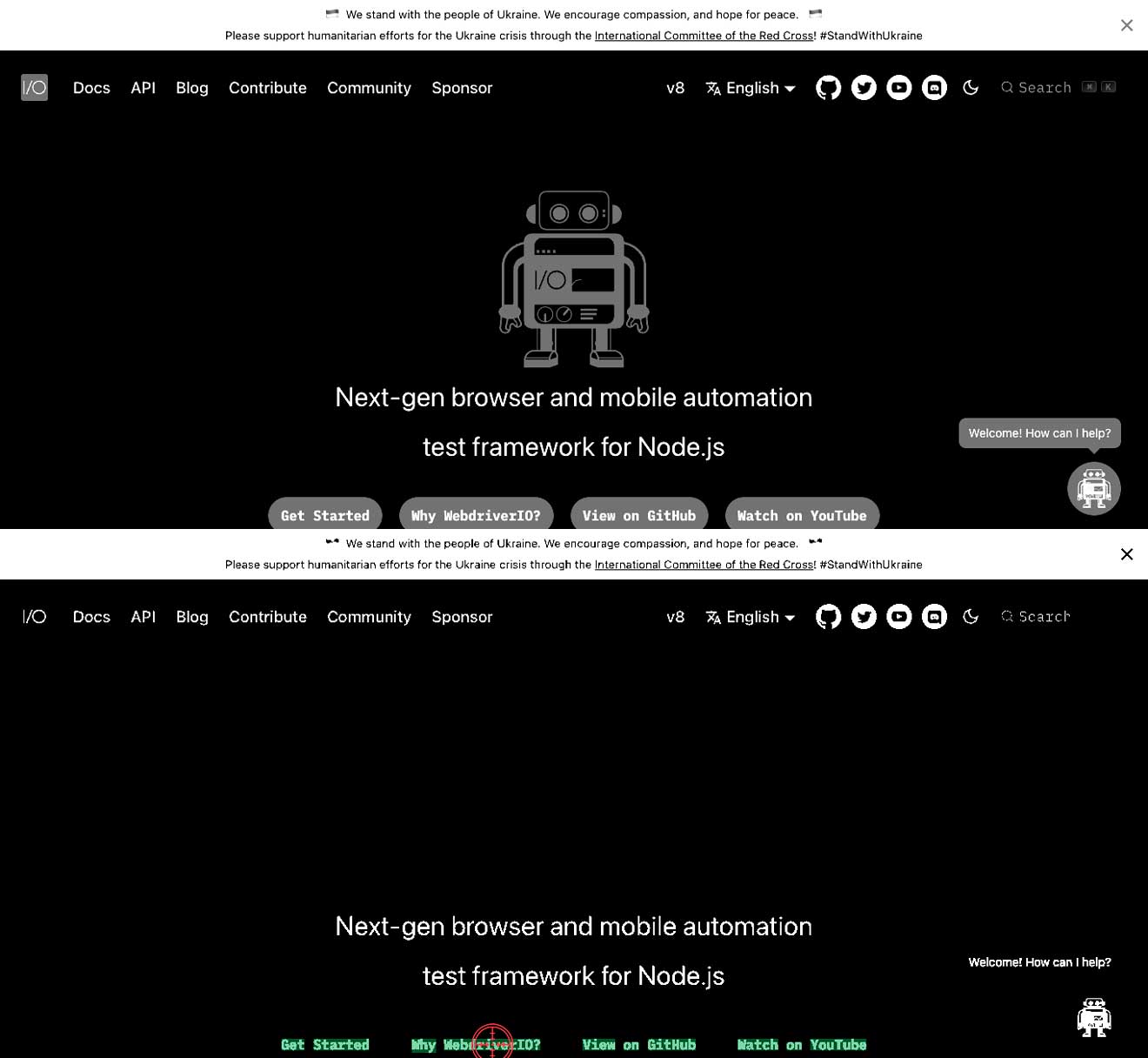
کنتراست بین متن و پسزمینه درست نیست
این بدان معناست که ممکن است متن روشن روی پسزمینه سفید یا متن تیره روی پسزمینه تیره داشته باشید. این میتواند منجر به عدم پیدا کردن متن شود. در مثالهای زیر میبینید که متن Why WebdriverIO? سفید است و توسط یک دکمه خاکستری احاطه شده است. در این حالت، منجر به عدم پیدا کردن متن Why WebdriverIO? میشود. با افزایش کنتراست برای دستور خاص، متن را پیدا میکند و میتواند روی آن کلیک کند، تصویر دوم را ببینید.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // With the default contrast of 0.25, the text is not found
contrast: 1,
});
چرا روی عنصر من کلیک میشود اما صفحه کلید روی دستگاههای موبایل من هرگز ظاهر نمیشود؟
این میتواند در برخی فیلدهای متنی رخ دهد که در آن کلیک بیش از حد طولانی تلقی میشود و به عنوان یک لمس طولانی در نظر گرفته میشود. میتوانید از گزینه clickDuration در ocrClickOnText و ocrSetValue برای رفع این مشکل استفاده کنید. اینجا را ببینید.
آیا این ماژول میتواند چندین عنصر را مانند WebdriverIO معمولی برگرداند؟
خیر، این در حال حاضر امکانپذیر نیست. اگر ماژول چندین عنصر را پیدا کند که با سلکتور ارائه شده مطابقت دارند، به طور خودکار عنصری را پیدا میکند که بالاترین امتیاز مطابقت را دارد.
آیا میتوانم برنامه خود را کاملاً با دستورات OCR ارائه شده توسط این سرویس خودکارسازی کنم؟
م�ن هرگز این کار را نکردهام، اما در تئوری، باید امکانپذیر باشد. لطفاً اگر موفق شدید به ما اطلاع دهید ☺️.
فایل اضافهای به نام {languageCode}.traineddata اضافه شده میبینم، این چیست؟
{languageCode}.traineddata یک فایل داده زبان است که توسط Tesseract استفاده میشود. این فایل حاوی دادههای آموزشی برای زبان انتخاب شده است که شامل اطلاعات لازم برای Tesseract برای تشخیص موثر کاراکترها و کلمات انگلیسی است.
محتویات {languageCode}.traineddata
این فایل معمولاً شامل:
- دادههای مجموعه کاراکتر: اطلاعات در مورد کاراکترهای زبان انگلیسی.
- مدل زبان: یک مدل آماری از چگونگی تشکیل کلمات توسط کاراکترها و جملات توسط کلما�ت.
- استخراجکنندههای ویژگی: دادههایی در مورد چگونگی استخراج ویژگیها از تصاویر برای تشخیص کاراکترها.
- دادههای آموزشی: دادههای حاصل از آموزش Tesseract بر روی مجموعه بزرگی از تصاویر متن انگلیسی.
چرا {languageCode}.traineddata مهم است؟
- تشخیص زبان: Tesseract به این فایلهای داده آموزشدیده برای تشخیص دقیق و پردازش متن در یک زبان خاص متکی است. بدون
{languageCode}.traineddata، Tesseract قادر به تشخیص متن انگلیسی نخواهد بود. - عملکرد: کیفیت و دقت OCR مستقیماً با کیفیت دادههای آموزشی مرتبط است. استفاده از فایل داده آموزشدیده صحیح اطمینان میدهد که فرآیند OCR تا حد ممکن دقیق است.
- سازگاری: اطمینان از اینکه فایل
{languageCode}.traineddataدر پروژه شما گنجانده شده است، تکرار محیط OCR در سیستمهای مختلف یا ماشینهای اعضای تیم را آسانتر میکند.
نسخهبندی {languageCode}.traineddata
گنجاندن {languageCode}.traineddata در سیستم کنترل نسخه شما به دلایل زیر توصیه میشود:
- سازگاری: این اطمینان میدهد که همه اعضای تیم یا محیطهای استقرار از همان نسخه دادههای آموزشی استفاده میکنند، که منجر به نتایج OCR سازگار در محیطهای مختلف میشود.
- تکرارپذیری: ذخیره این فایل در کنترل نسخه، بازتولید نتایج را هنگام اجرای فرآیند OCR در تاریخ بعدی یا در یک ماشین متفاوت آسانتر میکند.
- مدیریت وابستگی: گنجاندن آن در سیستم کنترل نسخه به مدیریت وابستگیها کمک میکند و اطمینان میدهد که هر راهاندازی یا پیکربندی محیط شامل فایلهای ضروری برای اجرای صحیح پروژه است.
آیا راه آسانی برای دیدن متنی که در صفحه من پیدا میشود بدون اجرای تست وجود دارد؟
بله، میتوانید از ویزارد CLI ما برای این منظور استفاده کنید. مستندات را میتوانید اینجا بیابید
