Häufig gestellte Fragen
Meine Tests sind sehr langsam
Wenn Sie diesen @wdio/ocr-service verwenden, nutzen Sie ihn nicht, um Ihre Tests zu beschleunigen, sondern weil Sie Schwierigkeiten haben, Elemente in Ihrer Web-/Mobile-App zu lokalisieren und einen einfacheren Weg suchen, sie zu finden. Und wir alle wissen hoffentlich, dass wenn man etwas will, man etwas anderes verliert. Aber...., es gibt eine Möglichkeit, den @wdio/ocr-service schneller als normal auszuführen. Weitere Informationen dazu finden Sie hier.
Kann ich die Befehle dieses Services mit den Standard-WebdriverIO-Befehlen/Selektoren kombinieren?
Ja, Sie können die Befehle kombinieren, um Ihr Skript noch leistungsfähiger zu machen! Es wird empfohlen, so weit wie möglich die Standard-WebdriverIO-Befehle/Selektoren zu verwenden und diesen Service nur dann zu nutzen, wenn Sie keinen eindeutigen Selektor finden können oder Ihr Selektor zu anfällig wird.
Mein Text wird nicht gefunden, wie ist das möglich?
Zunächst ist es wichtig zu verstehen, wie der OCR-Prozess in diesem Modul funktioniert. Bitte lesen Sie diese Seite. Wenn Sie Ihren Text immer noch nicht finden können, können Sie Folgendes versuchen.
Der Bildbereich ist zu groß
Wenn das Modul einen großen Bereich des Screenshots verarbeiten muss, findet es möglicherweise den Text nicht. Sie können einen kleineren Bereich angeben, indem Sie bei der Verwendung eines Befehls einen Haystack bereitstellen. Bitte prüfen Sie in den Befehlen, welche Befehle die Bereitstellung eines Haystacks unterstützen.
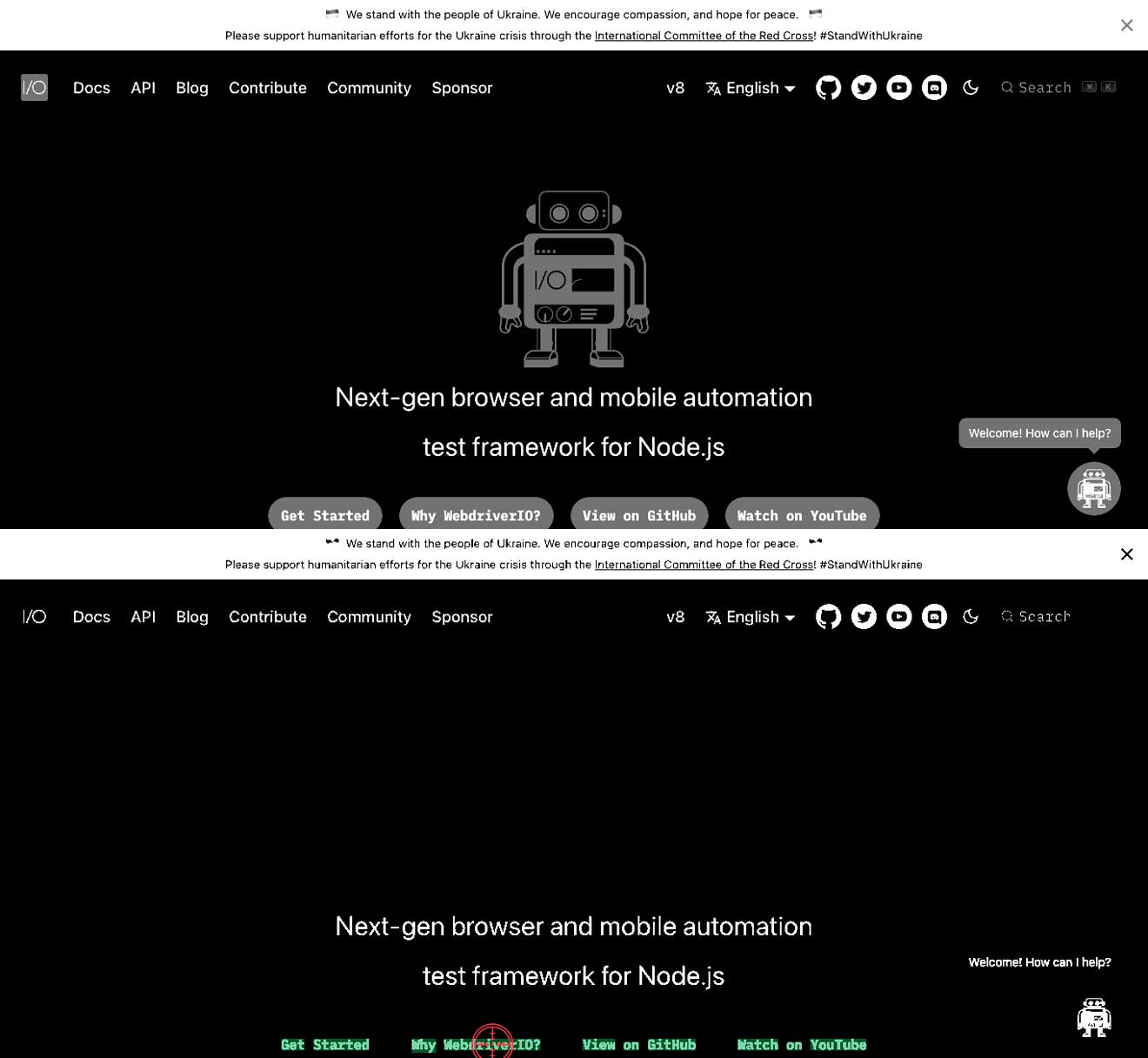
Der Kontrast zwischen Text und Hintergrund ist nicht korrekt
Das bedeutet, dass Sie möglicherweise hellen Text auf weißem Hintergrund oder dunklen Text auf dunklem Hintergrund haben. Dies kann dazu führen, dass Text nicht gefunden wird. In den Beispielen unten sehen Sie, dass der Text Why WebdriverIO? weiß ist und von einer grauen Schaltfläche umgeben ist. In diesem Fall wird der Text Why WebdriverIO? nicht gefunden. Durch Erhöhung des Kontrasts für den spezifischen Befehl wird der Text gefunden und kann angeklickt werden, siehe das zweite Bild.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // Mit dem Standardkontrast von 0,25 wird der Text nicht gefunden
contrast: 1,
});
Warum wird mein Element angeklickt, aber die Tastatur auf meinen mobilen Geräten erscheint nie?
Dies kann bei einigen Textfeldern passieren, bei denen der Klick als zu lang bestimmt und als langer Tipp betrachtet wird. Sie können die Option clickDuration bei ocrClickOnText und ocrSetValue verwenden, um dies zu beheben. Siehe hier.
Kann dieses Modul mehrere Elemente zurückgeben, wie es WebdriverIO normalerweise kann?
Nein, das ist derzeit nicht möglich. Wenn das Modul mehrere Elemente findet, die dem angegebenen Selektor entsprechen, wird automatisch das Element mit der höchsten Übereinstimmungsbewertung ausgewählt.
Kann ich meine App vollständig mit den OCR-Befehlen dieses Services automatisieren?
Ich habe es nie gemacht, aber theoretisch sollte es möglich sein. Bitte lassen Sie uns wissen, wenn Sie damit Erfolg haben ☺️.
Ich sehe eine zusätzliche Datei namens {languageCode}.traineddata, was ist das?
{languageCode}.traineddata ist eine Sprachdatendatei, die von Tesseract verwendet wird. Sie enthält die Trainingsdaten für die ausgewählte Sprache, die die notwendigen Informationen für Tesseract enthält, um englische Zeichen und Wörter effektiv zu erkennen.
Inhalt von {languageCode}.traineddata
Die Datei enthält in der Regel:
- Zeichensatzdaten: Informationen über die Zeichen in der englischen Sprache.
- Sprachmodell: Ein statistisches Modell darüber, wie Zeichen Wörter und Wörter Sätze bilden.
- Feature-Extraktoren: Daten darüber, wie Features aus Bildern für die Erkennung von Zeichen extrahiert werden.
- Trainingsdaten: Daten, die aus dem Training von Tesseract mit einer großen Menge englischer Textbilder abgeleitet wurden.
Warum ist {languageCode}.traineddata wichtig?
- Spracherkennung: Tesseract ist auf diese trainierten Datendateien angewiesen, um Text in einer bestimmten Sprache genau zu erkennen und zu verarbeiten. Ohne
{languageCode}.traineddatakönnte Tesseract keinen englischen Text erkennen. - Leistung: Die Qualität und Genauigkeit der OCR hängen direkt von der Qualität der Trainingsdaten ab. Die Verwendung der richtigen trainierten Datendatei stellt sicher, dass der OCR-Prozess so genau wie möglich ist.
- Kompatibilität: Sicherstellen, dass die Datei
{languageCode}.traineddatain Ihrem Projekt enthalten ist, erleichtert die Replikation der OCR-Umgebung auf verschiedenen Systemen oder Maschinen von Teammitgliedern.
Versionierung von {languageCode}.traineddata
Die Aufnahme von {languageCode}.traineddata in Ihr Versionskontrollsystem wird aus folgenden Gründen empfohlen:
- Konsistenz: Es stellt sicher, dass alle Teammitglieder oder Bereitstellungsumgebungen genau dieselbe Version der Trainingsdaten verwenden, was zu konsistenten OCR-Ergebnissen in verschiedenen Umgebungen führt.
- Reproduzierbarkeit: Die Speicherung dieser Datei in der Versionskontrolle erleichtert die Reproduktion von Ergebnissen, wenn der OCR-Prozess zu einem späteren Zeitpunkt oder auf einem anderen Computer ausgeführt wird.
- Abhängigkeitsmanagement: Die Aufnahme in das Versionskontrollsystem hilft bei der Verwaltung von Abhängigkeiten und stellt sicher, dass jede Einrichtung oder Umgebungskonfiguration die notwendigen Dateien für die korrekte Ausführung des Projekts enthält.
Gibt es eine einfache Möglichkeit zu sehen, welcher Text auf meinem Bildschirm gefunden wird, ohne einen Test auszuführen?
Ja, Sie können unseren CLI-Assistenten dafür verwenden. Die Dokumentation finden Sie hier
