Questions Fréquemment Posées
Mes tests sont très lents
Lorsque vous utilisez ce @wdio/ocr-service, vous ne l'utilisez pas pour accélérer vos tests, vous l'utilisez parce que vous avez du mal à localiser des éléments dans votre application web/mobile, et vous voulez un moyen plus facile de les localiser. Et nous savons tous, espérons-le, que lorsque vous voulez quelque chose, vous perdez autre chose. Mais..., il existe un moyen de faire exécuter le @wdio/ocr-service plus rapidement que la normale. Plus d'informations à ce sujet peuvent être trouvées ici.
Puis-je utiliser les commandes de ce service avec les commandes/sélecteurs par défaut de WebdriverIO ?
Oui, vous pouvez combiner les commandes pour rendre votre script encore plus puissant ! Le conseil est d'utiliser les commandes/sélecteurs par défaut de WebdriverIO autant que possible et de n'utiliser ce service que lorsque vous ne pouvez pas trouver un sélecteur unique, ou que votre sélecteur deviendrait trop fragile.
Mon texte n'est pas trouvé, comment est-ce possible ?
Tout d'abord, il est important de comprendre comment fonctionne le processus OCR dans ce module, alors veuillez lire cette page. Si vous ne trouvez toujours pas votre texte, vous pouvez essayer les choses suivantes.
La zone d'image est trop grande
Lorsque le module doit traiter une grande zone de la capture d'écran, il peut ne pas trouver le texte. Vous pouvez fournir une zone plus petite en fournissant un haystack lorsque vous utilisez une commande. Veuillez vérifier les commandes qui prennent en charge la fourniture d'un haystack.
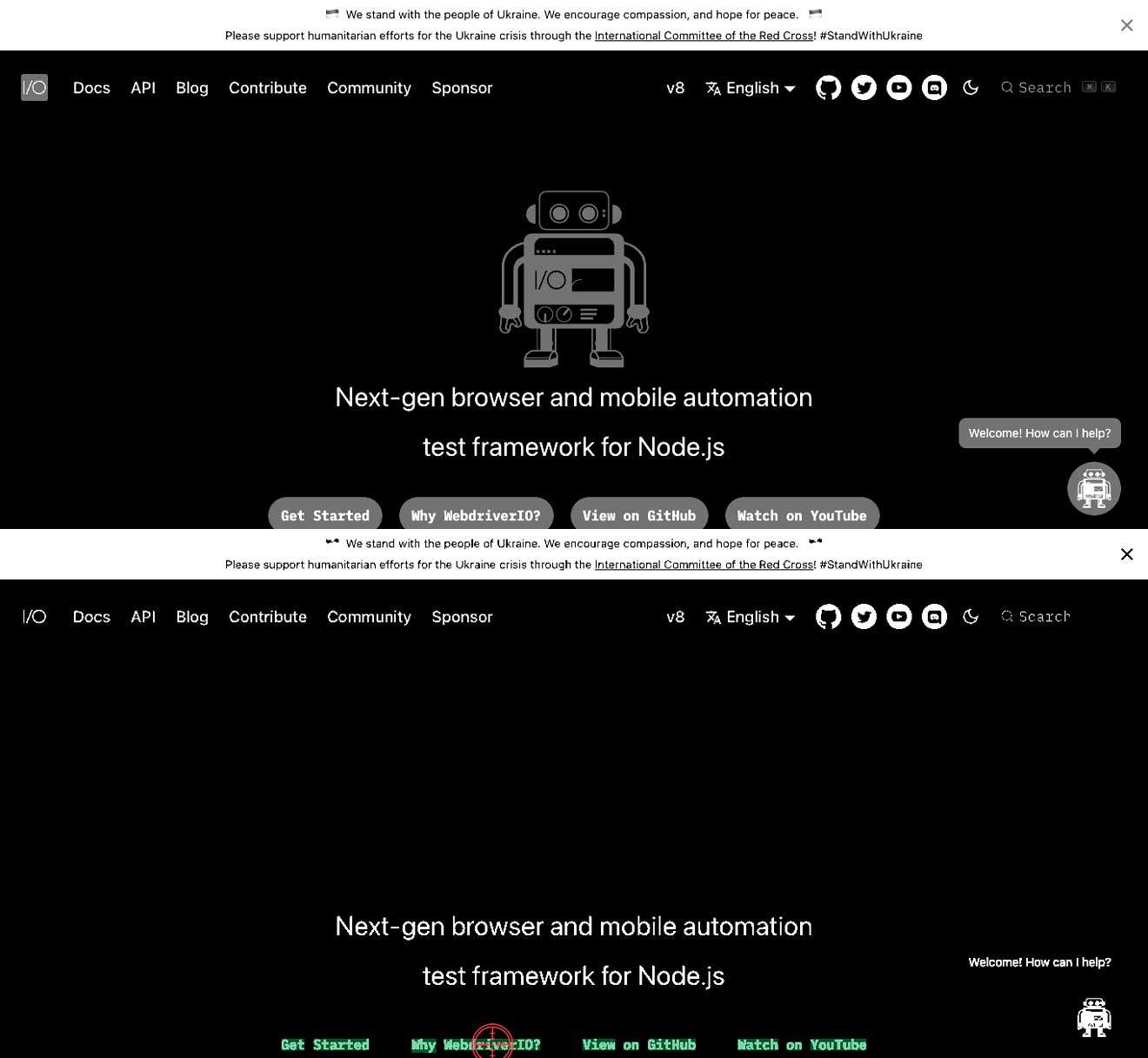
Le contraste entre le texte et l'arrière-plan n'est pas correct
Cela signifie que vous pourriez avoir un texte clair sur un fond blanc ou un texte foncé sur un fond foncé. Cela peut entraîner l'impossibilité de trouver du texte. Dans les exemples ci-dessous, vous pouvez voir que le texte Why WebdriverIO? est blanc et entouré d'un bouton gris. Dans ce cas, cela entraînera l'impossibilité de trouver le texte Why WebdriverIO?. En augmentant le contraste pour la commande spécifique, il trouve le texte et peut cliquer dessus, voir la deuxième image.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // Avec le contraste par défaut de 0,25, le texte n'est pas trouvé
contrast: 1,
});
Pourquoi mon élément est-il cliqué mais le clavier de mes appareils mobiles n'apparaît jamais ?
Cela peut se produire sur certains champs de texte où le clic est déterminé trop long et considéré comme un appui prolongé. Vous pouvez utiliser l'option clickDuration sur ocrClickOnText et ocrSetValue pour atténuer cela. Voir ici.
Ce module peut-il renvoyer plusieurs éléments comme WebdriverIO le fait normalement ?
Non, ce n'est actuellement pas possible. Si le module trouve plusieurs éléments qui correspondent au sélecteur fourni, il trouvera automatiquement l'élément qui a le score de correspondance le plus élevé.
Puis-je automatiser complètement mon application avec les commandes OCR fournies par ce service ?
Je ne l'ai jamais fait, mais en théorie, cela devrait être possible. Veuillez nous faire savoir si vous y parvenez ☺️.
Je vois un fichier supplémentaire appelé {languageCode}.traineddata être ajouté, qu'est-ce que c'est ?
{languageCode}.traineddata est un fichier de données linguistiques utilisé par Tesseract. Il contient les données d'entraînement pour la langue sélectionnée, qui comprend les informations nécessaires à Tesseract pour reconnaître efficacement les caractères et les mots en anglais.
Contenu de {languageCode}.traineddata
Le fichier contient généralement :
- Données de jeu de caractères : Informations sur les caractères de la langue anglaise.
- Modèle de langue : Un modèle statistique de la façon dont les caractères forment des mots et les mots forment des phrases.
- Extracteurs de caractéristiques : Données sur la façon d'extraire des caractéristiques des images pour la reconnaissance des caractères.
- Données d'entraînement : Données dérivées de l'entraînement de Tesseract sur un grand ensemble d'images de texte en anglais.
Pourquoi {languageCode}.traineddata est-il important ?
- Reconnaissance de la langue : Tesseract s'appuie sur ces fichiers de données entraînées pour reconnaître et traiter avec précision le texte dans une langue spécifique. Sans
{languageCode}.traineddata, Tesseract ne serait pas capable de reconnaître le texte en anglais. - Performance : La qualité et la précision de l'OCR sont directement liées à la qualité des données d'entraînement. L'utilisation du bon fichier de données entraînées garantit que le processus OCR est aussi précis que possible.
- Compatibilité : S'assurer que le fichier
{languageCode}.traineddataest inclus dans votre projet facilite la réplication de l'environnement OCR sur différents systèmes ou machines des membres de l'équipe.
Versionnement de {languageCode}.traineddata
L'inclusion de {languageCode}.traineddata dans votre système de contrôle de version est recommandée pour les raisons suivantes :
- Cohérence : Cela garantit que tous les membres de l'équipe ou les environnements de déploiement utilisent exactement la même version des données d'entra�înement, ce qui conduit à des résultats OCR cohérents dans différents environnements.
- Reproductibilité : Stocker ce fichier dans le contrôle de version facilite la reproduction des résultats lors de l'exécution du processus OCR à une date ultérieure ou sur une machine différente.
- Gestion des dépendances : L'inclure dans le système de contrôle de version aide à gérer les dépendances et garantit que toute configuration ou configuration d'environnement inclut les fichiers nécessaires pour que le projet s'exécute correctement.
Existe-t-il un moyen simple de voir quel texte est trouvé sur mon écran sans exécuter un test ?
Oui, vous pouvez utiliser notre assistant CLI pour cela. La documentation peut être trouvée ici
