Часті запитання
Мої тести виконуються дуже повільно
Коли ви використовуєте @wdio/ocr-service, ви використовуєте його не для прискорення тестів, а тому що вам складно знаходити елементи у вашому веб/мобільному додатку, і ви хочете простіший спосіб їх знаходження. І ми всі, сподіваюся, знаємо, що коли ви щось отримуєте, ви щось втрачаєте. Але..., є спосіб зробити @wdio/ocr-service швидшим за звичайний. Більше інформації про це можна знайти тут.
Чи можу я використовувати команди з цього сервісу разом із стандартними командами/селекторами WebdriverIO?
Так, ви можете комбінувати команди, щоб зробити ваш скрипт ще потужнішим! Рекомендується використовувати стандартні команди/селектори WebdriverIO якомога більше і використовувати цей сервіс лише тоді, коли ви не можете знайти унікальний селектор, або ваш селектор стане занадто крихким.
Мій текст не знайдено, як це можливо?
Спочатку важливо зрозуміти, як працює процес OCR у цьому модулі, тому, будь ласка, прочитайте цю сторінку. Якщо ви все ще не можете знайти свій текст, ви можете спробувати наступні речі.
Область зображення занадто велика
Коли модуль повинен �обробити велику область скріншоту, він може не знайти текст. Ви можете надати меншу область, вказавши haystack при використанні команди. Будь ласка, перевірте команди, щоб дізнатися, які команди підтримують надання haystack.
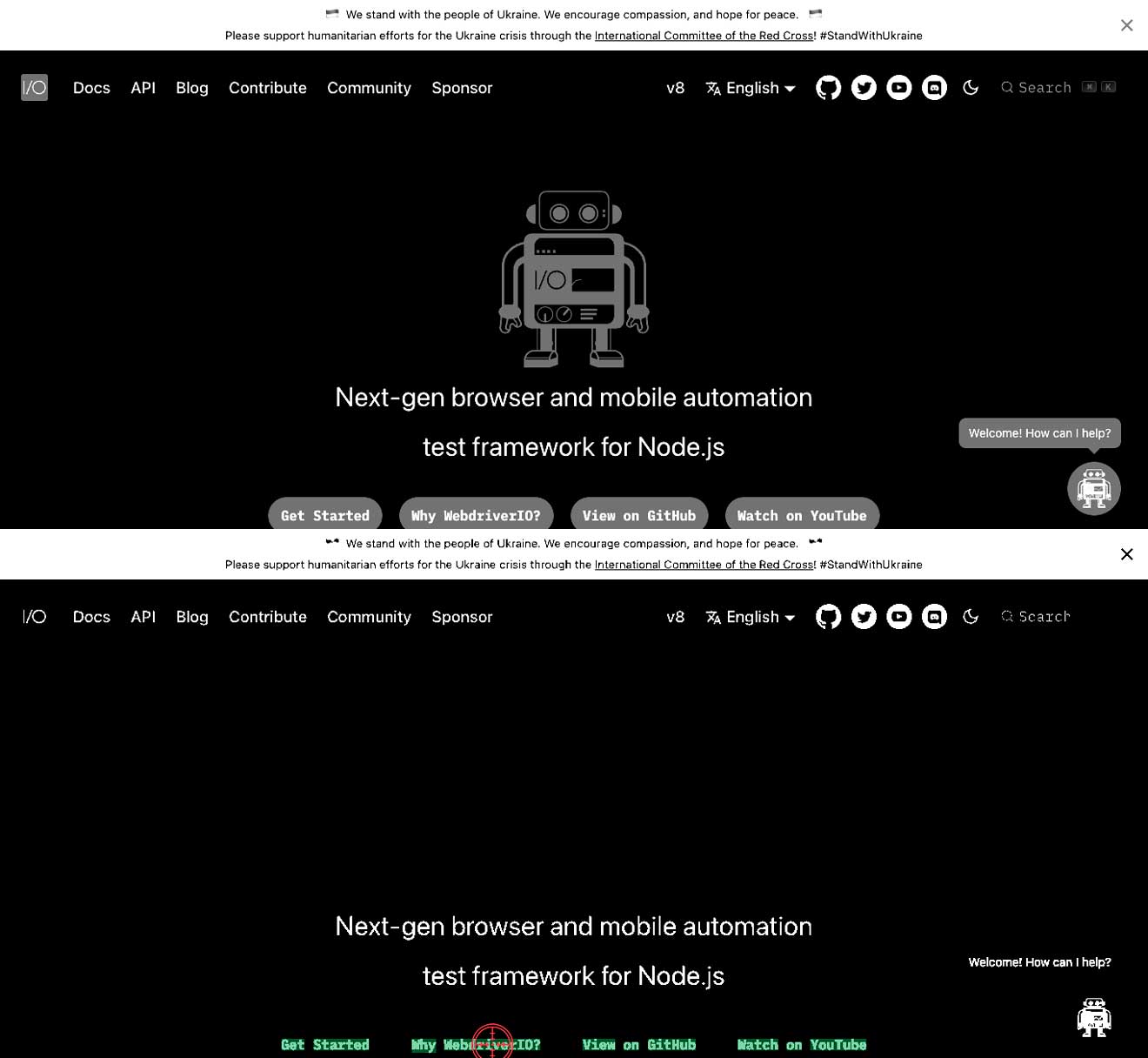
Контраст між текстом і фоном неправильний
Це означає, що у вас може бути світлий текст на білому фоні або темний текст на темному фоні. Це може призвести до неможливості знайти текст. У прикладах нижче ви можете побачити, що текст Why WebdriverIO? є білим і оточений сірою кнопкою. У цьому випадку текст Why WebdriverIO? не буде знайдено. Збільшивши контраст для конкретної команди, вона знаходить текст і може клікнути на нього, див. друге зображення.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // З типовим контрастом 0.25 текст не знайдено
contrast: 1,
});
Чому елемент клікається, але клавіатура на моїх мобільних пристроях не з'являється?
Це може статися на деяких текстових полях, де клік визначається як занадто довгий і вважається довгим натисканням. Ви можете використовувати опцію clickDuration у ocrClickOnText та ocrSetValue, щоб усунути цю проблему. Дивіться тут.
Чи може цей модуль повертати кілька елементів, як це зазвичай робить WebdriverIO?
Ні, на даний момент це неможливо. Якщо модуль знаходить кілька елементів, що відповідають наданому селектору, він автоматично знайде елемент з найвищим показником відповідності.
Чи можу я повністю автоматизувати свій додаток за допомогою OCR-команд, які надає цей сервіс?
Я ніколи цього не робив, але теоретично це повинно бути можливо. Будь ласка, повідомте нам, якщо вам це вдасться ☺️.
Я бачу додатковий файл з назвою {languageCode}.traineddata, що це таке?
{languageCode}.traineddata — це файл мовних даних, який використовується Tesseract. Він містить тренувальні дані для вибраної мови, які включають необхідну інформацію для ефективного розпізнавання символів та слів англійською мовою Tesseract.
Вміст {languageCode}.traineddata
Файл зазвичай містить:
- Дані набору символів: Інформація про символи англійської мови.
- Мовна модель: Статистична модель того, як символи формують слова, а слова формують речення.
- Екстрактори ознак: Дані про те, як витягувати ознаки з зображень для розпізнавання сим�волів.
- Тренувальні дані: Дані, отримані при навчанні Tesseract на великому наборі зображень англійського тексту.
Чому {languageCode}.traineddata важливий?
- Розпізнавання мови: Tesseract покладається на ці тренувальні файли даних для точного розпізнавання та обробки тексту конкретною мовою. Без
{languageCode}.traineddataTesseract не зможе розпізнавати англійський текст. - Продуктивність: Якість і точність OCR безпосередньо пов'язані з якістю тренувальних даних. Використання правильного файлу тренувальних даних забезпечує максимальну точність процесу OCR.
- Сумісність: Включення файлу
{languageCode}.traineddataу ваш проект полегшує відтворення середовища OCR на різних системах або на машинах різних членів команди.
Версіонування {languageCode}.traineddata
Включення {languageCode}.traineddata у вашу систему контролю версій рекомендується з таких причин:
- Узгодженість: Це гарантує, що всі члени команди або середовища розгортання використовують саме ту ж версію тренувальних даних, що призводить до однакових результатів OCR у різних середовищах.
- Відтворюваність: Зберігання цього файлу в системі контролю версій полегшує відтворення результатів при запуску процесу OCR пізніше або на іншій машині.
- Управління залежностями: Включення його в систему контролю версій допомагає в управлінні залежностями та гарантує, що будь-яка установка або конфігурація середовища включає необхідні файли для правильної роботи проекту.
Чи є простий спосіб побачити, який текст знайдено на моєму екрані, без запуску тесту?
Так, ви можете використовувати наш майстер CLI для цього. Документацію можна знайти тут
