Preguntas Frecuentes
Mis pruebas son muy lentas
Cuando estás utilizando este @wdio/ocr-service no lo estás usando para acelerar tus pruebas, lo usas porque tienes dificultades para localizar elementos en tu aplicación web/móvil, y quieres una forma más fácil de localizarlos. Y todos esperamos saber que cuando quieres algo, pierdes otra cosa. Pero..., hay una manera de hacer que el @wdio/ocr-service se ejecute más rápido de lo normal. Más información sobre esto se puede encontrar aquí.
¿Puedo usar los comandos de este servicio con los comandos/selectores predeterminados de WebdriverIO?
¡Sí, puedes combinar los comandos para hacer tu script aún más potente! El consejo es usar los comandos/selectores predeterminados de WebdriverIO tanto como sea posible y solo usar este servicio cuando no puedas encontrar un selector único, o tu selector se vuelva demasiado frágil.
Mi texto no se encuentra, ¿cómo es posible?
Primero, es importante entender cómo funciona el proceso de OCR en este módulo, así que por favor lee esta página. Si aún no puedes encontrar tu texto, puedes intentar las siguientes cosas.
El área de la imagen es demasiado grande
Cuando el módulo necesita procesar un área grande de la captura de pantalla, es posible que no encuentre el texto. Puedes proporcionar un área más pequeña proporcionando un haystack cuando uses un comando. Por favor, consulta los comandos que admiten proporcionar un haystack.
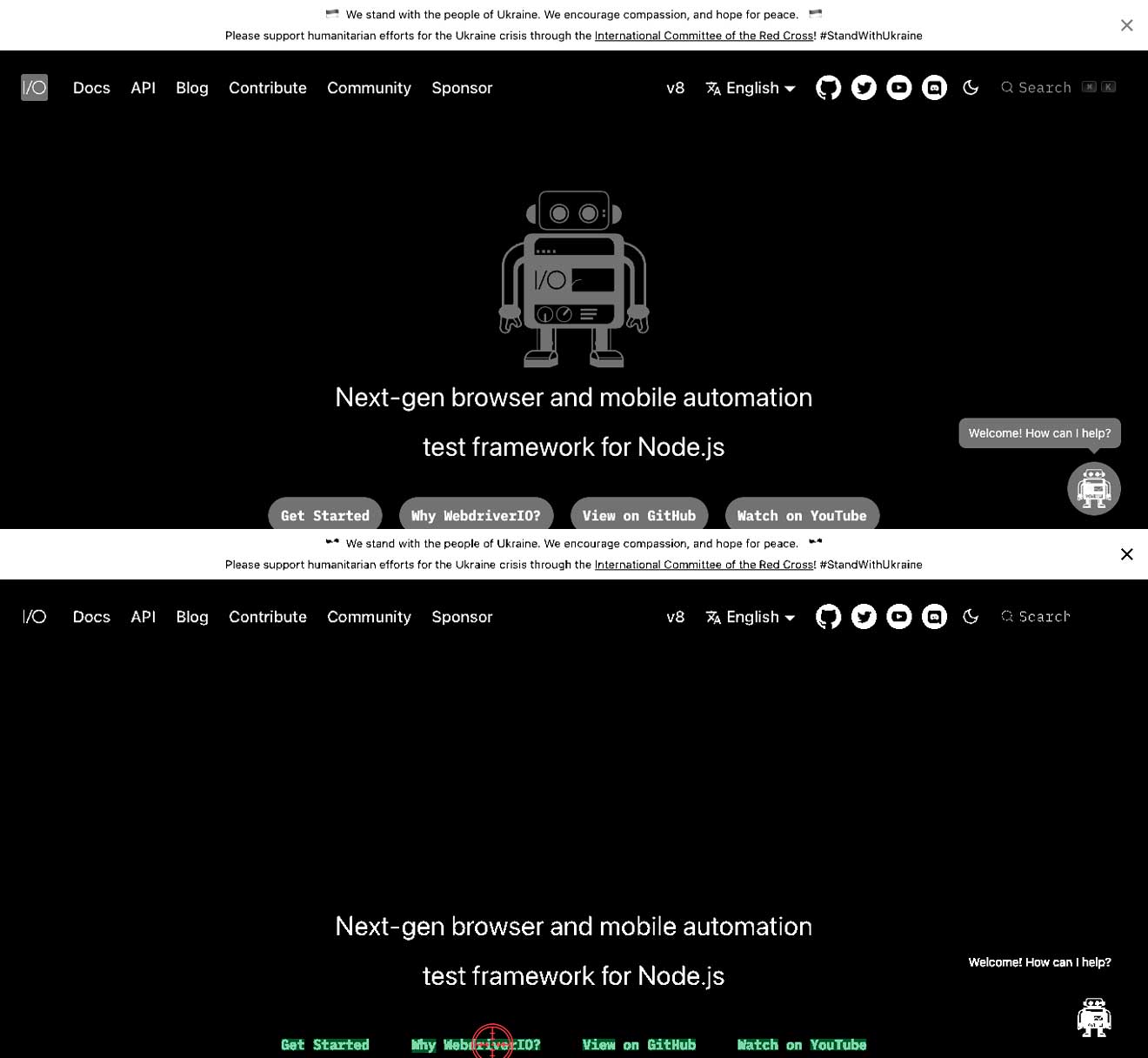
El contraste entre el texto y el fondo no es correcto
Esto significa que puedes tener texto claro sobre un fondo blanco o texto oscuro sobre un fondo oscuro. Esto puede resultar en no poder encontrar el texto. En los ejemplos a continuación, puedes ver que el texto Why WebdriverIO? es blanco y está rodeado por un botón gris. En este caso, resultará en no encontrar el texto Why WebdriverIO?. Al aumentar el contraste para el comando específico, encuentra el texto y puede hacer clic en él, ver la segunda imagen.
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // Con el contraste predeterminado de 0.25, el texto no se encuentra
contrast: 1,
});
¿Por qué se hace clic en mi elemento pero el teclado en mis dispositivos móviles nunca aparece?
Esto puede suceder en algunos campos de texto donde el clic se determina demasiado largo y se considera un toque prolongado. Puedes usar la opción clickDuration en ocrClickOnText y ocrSetValue para aliviar esto. Ver aquí.
¿Puede este módulo proporcionar múltiples elementos como normalmente puede hacer WebdriverIO?
No, esto actualmente no es posible. Si el módulo encuentra múltiples elementos que coinciden con el selector proporcionado, automáticamente encontrará el elemento que tiene la puntuación de coincidencia más alta.
¿Puedo automatizar completamente mi aplicación con los comandos OCR proporcionados por este servicio?
Nunca lo he hecho, pero en teoría, debería ser posible. Por favor, háznos saber si tienes éxito con eso ☺️.
Veo un archivo adicional llamado {languageCode}.traineddata que se agrega, ¿qué es esto?
{languageCode}.traineddata es un archivo de datos de idioma utilizado por Tesseract. Contiene los datos de entrenamiento para el idioma seleccionado, que incluye la información necesaria para que Tesseract reconozca caracteres y palabras en inglés de manera efectiva.
Contenido de {languageCode}.traineddata
El archivo generalmente contiene:
- Datos del conjunto de caracteres: Información sobre los caracteres en el idioma inglés.
- Modelo de idioma: Un modelo estadístico de cómo los caracteres forman palabras y las palabras forman oraciones.
- Extractores de características: Datos sobre cómo extraer características de imágenes para el reconocimiento de caracteres.
- Datos de entrenamiento: Datos derivados del entrenamiento de Tesseract en un gran conjunto de imágenes de texto en inglés.
¿Por qué es importante {languageCode}.traineddata?
- Reconocimiento de idioma: Tesseract depende de estos archivos de datos entrenados para reconocer y procesar con precisión el texto en un idioma específico. Sin
{languageCode}.traineddata, Tesseract no podría reconocer texto en inglés. - Rendimiento: La calidad y precisión del OCR están directamente relacionadas con la calidad de los datos de entrenamiento. Usar el archivo de datos entrenado correcto asegura que el proceso de OCR sea lo más preciso posible.
- Compatibilidad: Asegurar que el archivo
{languageCode}.traineddataesté incluido en tu proyecto facilita la replicación del entorno OCR en diferentes sistemas o máquinas de los miembros del equipo.
Versionado de {languageCode}.traineddata
Se recomienda incluir {languageCode}.traineddata en tu sistema de control de versiones por las siguientes razones:
- Consistencia: Asegura que todos los miembros del equipo o entornos de implementación utilicen exactamente la misma versión de los datos de entrenamiento, lo que lleva a resultados de OCR consistentes en diferentes entornos.
- Reproducibilidad: Almacenar este archivo en el control de versiones facilita la reproducción de resultados al ejecutar el proceso de OCR en una fecha posterior o en una máquina diferente.
- Gestión de dependencias: Incluirlo en el sistema de control de versiones ayuda a gestionar las dependencias y asegura que cualquier configuración o configuración de entorno incluya los archivos necesarios para que el proyecto se ejecute correctamente.
¿Hay una manera fácil de ver qué texto se encuentra en mi pantalla sin ejecutar una prueba?
Sí, puedes usar nuestro asistente CLI para eso. La documentación se puede encontrar aquí
