अक्सर पूछे जाने वाले प्रश्न
मेरे टेस्ट बहुत धीमे हैं
जब आप @wdio/ocr-service का उपयोग कर रहे होते हैं, तो आप इसका उपयोग अपने टेस्ट को तेज करने के लिए नहीं कर रहे हैं, आप इसका उपयोग इसलिए करते हैं क्योंकि आपको अपने वेब/मोबाइल ऐप में एलिमेंट्स को ढूंढने में कठिनाई हो रही है, और आप उन्हें ढूंढने का एक आसान तरीका चाहते हैं। और हम सभी उम्मीद करते हैं कि जब आप कुछ चाहते हैं, तो आप कुछ और खो देते हैं। लेकिन...., @wdio/ocr-service को सामान्य से तेज़ी से चलाने का एक तरीका है। इसके बारे में अधिक जानकारी यहाँ पाई जा सकती है।
क्या मैं इस सर्विस के कमांड्स को डिफॉल्ट WebdriverIO कमांड्स/सिलेक्टर्स के साथ उपयोग कर सकता हूँ?
हां, आप अपनी स्क्रिप्ट को और भी शक्तिशाली बनाने के लिए कमांड्स को संयोजित कर सकते हैं! सलाह यह है कि जितना संभव हो सके डिफॉल्ट WebdriverIO कमांड्स/सिलेक्टर्स का उपयोग करें और केवल तभी इस सर्विस का उपयोग करें जब आप एक अद्वितीय सिलेक्टर नहीं ढूंढ सकते, या आपका सिलेक्टर बहुत नाजुक हो जाएगा।
मेरा टेक्स्ट नहीं मिला, यह कैसे संभव है?
सबसे पहले, यह समझना महत्वपूर्ण है कि इस मॉड्यूल में OCR प्रक्रिया कैसे काम करती है, इसलिए कृपया यह पृष्ठ पढ़ें। यदि आप अभी भी अपना टेक्स्ट नहीं ढूंढ पा रहे हैं, तो आप निम्नलिखित चीजों को आजमा सकते हैं।
इमेज क्षेत्र बहुत बड़ा है
जब मॉड्यूल को स्क्रीनशॉट के एक बड़े क्षेत्र को प्रोसेस करने की आवश्यकता होती है, तो यह टेक्स्ट को नही�ं ढूंढ सकता है। आप कमांड का उपयोग करते समय हेस्टैक प्रदान करके एक छोटा क्षेत्र प्रदान कर सकते हैं। कृपया कमांड्स देखें कि कौन-कौन से कमांड्स हेस्टैक प्रदान करने का समर्थन करते हैं।
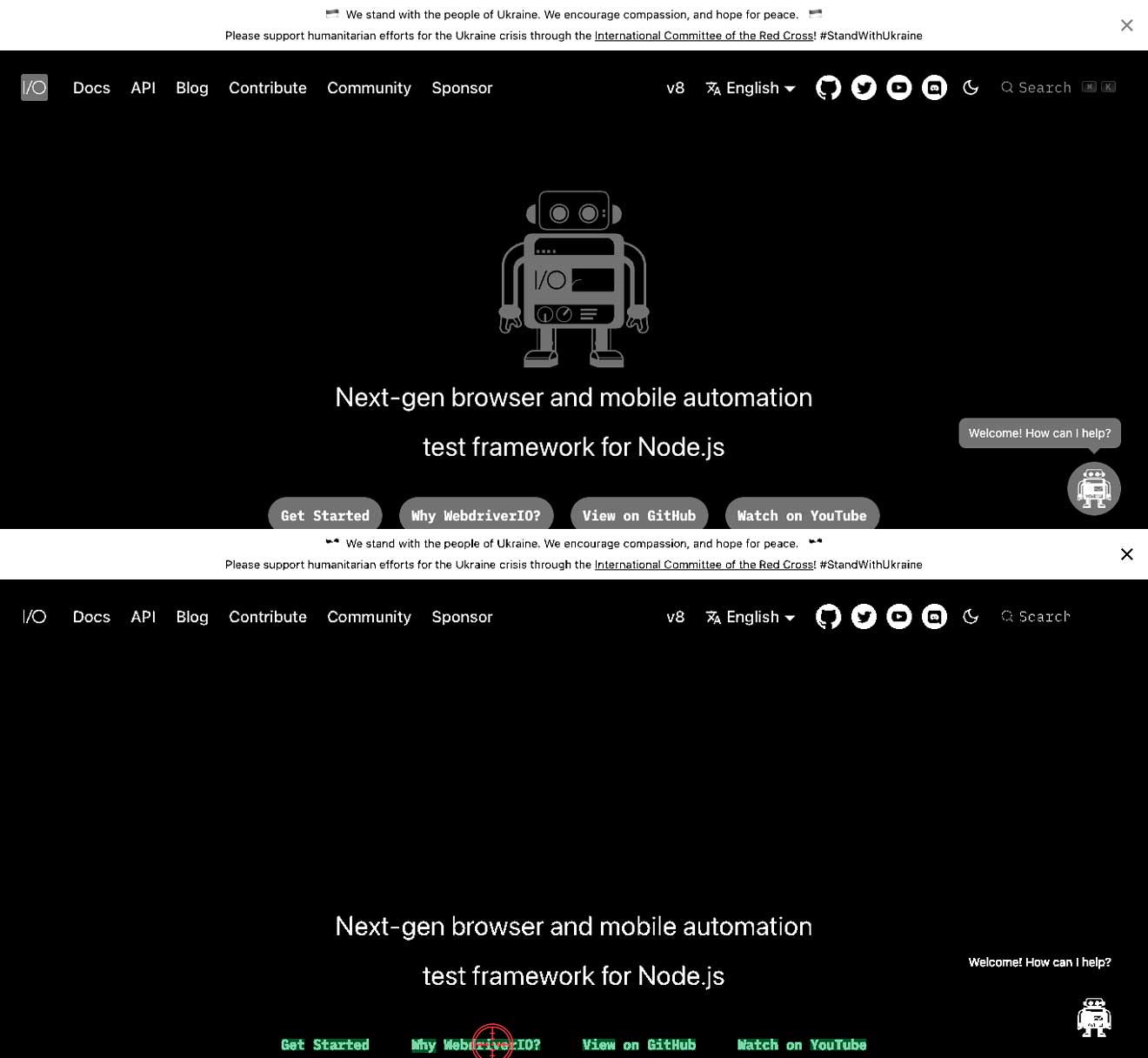
टेक्स्ट और बैकग्राउंड के बीच कंट्रास्ट सही नहीं है
इसका मतलब यह है कि आपके पास हल्का टेक्स्ट सफेद बैकग्राउंड पर या गहरा टेक्स्ट गहरे बैकग्राउंड पर हो सकता है। इससे टेक्स्ट को न ढूंढ पाने का परिणाम हो सकता है। नीचे दिए गए उदाहरणों में आप देख सकते हैं कि Why WebdriverIO? टेक्स्ट सफेद है और एक ग्रे बटन से घिरा हुआ है। इस मामले में, यह Why WebdriverIO? टेक्स्ट को नहीं ढूंढ पाएगा। विशिष्ट कमांड के लिए कंट्रास्ट बढ़ाकर यह टेक्स्ट ढूंढता है और उस पर क्लिक कर सकता है, दूसरी इमेज देखें।
await driver.ocrClickOnText({
haystack: { height: 44, width: 1108, x: 129, y: 590 },
text: "WebdriverIO?",
// // With the default contrast of 0.25, the text is not found
contrast: 1,
});
मेरे एलिमेंट पर क्लिक क्यों हो रहा है लेकिन मेरे मोबाइल डिवाइस पर कीबोर्ड कभी भी पॉप अप नहीं होता?
यह कुछ टेक्स्ट फील्ड्स पर हो सकता है जहां क्लिक को बहुत लंबा माना जाता है और इसे लंबे टैप के रूप में माना जाता है। आप इसे हल करने के लिए ocrClickOnText और ocrSetValue पर clickDuration विकल्प का उपयोग कर सकते हैं। यहां देखें।
क्या यह मॉड्यूल WebdriverIO की तरह कई एलिमेंट्स वापस दे सकता है?
नहीं, यह वर्तमान में संभव नहीं है। यदि मॉड्यूल कई एलिमेंट्स ढूंढता है जो प्रदान किए गए सिलेक्टर से मेल खाते हैं, तो यह स्वचालित रूप से उस एलिमेंट को ढूंढेगा जिसका मिलान स्कोर सबसे अधिक है।
क्या मैं इस सर्विस द्वारा प्रदान किए गए OCR कमांड्स के साथ अपने ऐप को पूरी तरह से ऑटोमेट कर सकता हूँ?
मैंने कभी ऐसा नहीं किया है, लेकिन सिद्धांत रूप में, यह संभव होना चाहिए। कृपया हमें बताएं यदि आप इसमें सफल होते हैं ☺️।
मुझे {languageCode}.traineddata नामक एक अतिरिक्त फ़ाइल जोड़ी जाती दिख रही है, यह क्या है?
{languageCode}.traineddata Tesseract द्वारा उपयोग की जाने वाली एक भाषा डेटा फ़ाइल है। इसमें चयनित भाषा के लिए प्रशिक्षण डेटा होता है, जिसमें Tesseract के लिए अंग्रेजी वर्णों और शब्दों को प्रभावी ढंग से पहचानने के लिए आवश्यक जानकारी शामिल होती है।
{languageCode}.traineddata की सामग्री
फ़ाइल में आमतौर पर शामिल हैं:
- वर्ण सेट डेटा: अंग्रेजी भाषा के वर्णों के बारे में जानकारी।
- भाषा मॉडल: यह एक सांख्यिकीय मॉडल है जो बताता है कि वर्ण कैसे शब्द बनाते हैं और शब्द कैसे वाक्य बनाते हैं।
- फीचर एक्सट्रैक्टर्स: वर्णों की पहचान के लिए चित्रों से फीचर्स निकालने के बारे में डेटा।
- प्रशिक्षण डेटा: अंग्रेजी टेक्स्ट चित्रों के एक बड़े सेट पर Tesseract को प्रशिक्षित करने से प्राप्त डेटा।
{languageCode}.traineddata क्यों महत्वपूर्ण है?
- भाषा पहचान: Tesseract एक विशिष्ट भाषा में टेक्स्ट को सटीक रूप से पहचानने और प्रोसेस करने के लिए इन प्रशिक्षित डेटा फ़ाइलों पर निर्भर करता है।
{languageCode}.traineddataके बिना, Tesseract अंग्रेजी टेक्स्ट को पहचानने में सक्षम नहीं होगा। - प्रदर्शन: OCR की गुणवत्ता और सटीकता सीधे प्रशिक्षण डेटा की गुणवत्ता से संबंधित है। सही प्रशिक्षित डेटा फ़ाइल का उपयोग करने से यह सुनिश्चित होता है कि OCR प्रक्रिया यथासंभव सटीक है।
- संगतता: यह सुनिश्चित करना कि
{languageCode}.traineddataफ़ाइल आपके प्रोजेक्ट में शामिल है, OCR वातावरण को विभिन्न सिस्टम या टीम के सदस्यों के मशीनों पर प्रतिकृति बनाना आसान बनाता है।
{languageCode}.traineddata का वर्जनिंग
आपके वर्जन कंट्रोल सिस्टम में {languageCode}.traineddata को शामिल करना निम्न कारणों से अनुशंसित है:
- निरंतरता: यह सुनिश्चित करता है कि सभी टीम सदस्य या डिप्लॉयमेंट वातावरण प्रशिक्षण डेटा के बिल्कुल समान वर्जन का उपयोग करें, जिससे विभिन्न वातावरणों में OCR परिणाम निरंतर होते हैं।
- पुनरुत्पादकता: इस फ़ाइल को वर्जन कंट्रोल में स्टोर करने से बाद में या एक अलग मशीन पर OCR प्रक्रिया चलाते समय परिणामों को पुनः उत्पन्न करना आसान हो जाता है।
- निर्भरता प्रबंधन: इसे वर्जन कंट्रोल सिस्टम में शामिल करने से निर्भरताओं के प्रबंधन में मदद मिलती है और यह सुनिश्चित होता है कि कोई भी सेटअप या वातावरण कॉन्फिगरेशन में प्रोजेक्ट को सही ढंग से चलाने के लिए आवश्यक फ़ाइलें शामिल हों।
क्या मेरी स्क्रीन पर कौन सा टेक्स्ट मिला है, यह देखने का कोई आसान तरीका है, बिना टेस्ट चलाए?
हां, आप इसके लिए हमारे CLI विज़ार्ड का उपयोग कर सकते हैं। दस्तावेज़ीकरण यहां पाया जा सकता है
